작성일: 2026년 1월 11일 주제: 구글의 AI 이미지 생성 도구 ‘나노바나나 프로’의 실제 활용 사례 및 분석
1. 나노바나나 프로란?
나노바나나 프로(Nano Banana Pro)는 구글 딥마인드가 2025년 11월 20일 출시한 최신 AI 이미지 생성 및 편집 모델입니다. 공식 명칭은 Gemini 3 Pro Image이며, 기존 나노바나나(Gemini 2.5 Flash Image 기반)를 대폭 업그레이드한 버전입니다.
탄생 배경
2025년 8월, AI 이미지 생성 모델 비교 사이트인 LM Arena에 정체불명의 “nano-banana”라는 모델이 등장했습니다. 이 모델은 기존 이미지 생성 모델들을 압도적으로 능가하는 품질과 사물 이해력으로 큰 화제를 모았고, 이후 구글이 공식적으로 정체를 밝히며 출시했습니다.
핵심 특징
| 기능 | 설명 |
|---|---|
| Perfect Text Rendering | 다국어로 선명하고 읽기 쉬운 텍스트 구현 |
| Thinking Mode | AI가 렌더링 전 구성을 계획하여 최적화된 결과 생성 |
| 2K/4K 해상도 | 고해상도 출력 지원 |
| 14개 참조 이미지 융합 | 스타일, 로고, 캐릭터 얼굴 학습 가능 |
| 5명 캐릭터 일관성 | 최대 5명의 인물 외형 특징 유지 |
| 구글 검색 통합 | 실시간 정보 기반 이미지 생성 |
2. 다국어 텍스트 렌더링 정확도
나노바나나 프로의 가장 강력한 기능 중 하나는 이미지 내 텍스트 렌더링입니다.
언어별 정확도
| 언어 | 정확도 | 비고 |
|---|---|---|
| 영어 | 94% | 가장 높은 정확도 |
| 한국어 | 90% | 한글의 체계적 구조 덕분에 높은 성능 |
| 중국어 | 88% | 복잡한 획수 문자에서 오류 발생 |
| 일본어 | 85% | 히라가나 > 가타카나 > 한자 순 정확도 |
실제 사례: 다국어 간판 변환
영어로 된 STOP 표지판을 한국어 ‘정지’ 간판으로 변환하는 테스트에서:
- 배경, 조명, 구도는 그대로 유지
- 텍스트만 깔끔하게 교체
- 기존 AI 모델에서 불가능했던 작업이 자연스럽게 구현
3. 실제 활용 사례
24가지 실제 활용 사례 개요
3.1 마케팅 콘텐츠 제작
소셜 미디어 그래픽
- LinkedIn, Instagram, TikTok용 시각 콘텐츠 제작
- 일반 스톡 사진 대신 브랜드 맞춤형 비주얼 생성
- 게시물 각도에 맞춘 정확한 시각화
활용 효과: 소셜 미디어 마케팅팀이 단일 캠페인 비주얼에서 다양한 포맷을 자동 생성하여 게시물 준비 시간을 75% 단축
유튜브 썸네일
- 클릭률(CTR)을 결정짓는 핵심 요소
- 영상의 주제와 분위기를 즉시 전달하는 강렬한 구도
- 대담한 비주얼 구성 자동화
3.2 이커머스 & 쇼핑몰 활용
상세페이지 자동화
핵심 워크플로우:
- 제품 사진과 기능 요약, 가격 정보를 하나의 페이지에 배치
- 포토샵 없이 쇼핑몰용 이미지 제작
- 지역 특산품의 품종별 특성을 이미지로 시각화
실제 성과:
- 상세페이지 이미지 1분 이내 생성
- 기획과 제작 시간 대폭 단축
- 제품 페이지 전환율 15-30% 향상 (보고된 사례 기준)
제품 사진 편집
| 작업 유형 | 설명 |
|---|---|
| 배경 교체 | 제품 주위 배경을 오피스 공간, 야외 등으로 변경 |
| 먼지/소품 제거 | 상업용 제품 사진 정리 |
| 조명 조화 | 제품과 배경의 조명 통일 |
| 라이프스타일 합성 | 제품 주변에 믿을 수 있는 환경 생성 |
3.3 인포그래픽 제작
특징
- 구글 검색 연동으로 실제 정보 기반 시각화
- 복잡한 내용을 아이콘, 도형, 텍스트로 정리
- 여행 가이드, 블로그, 인스타그램에 최적화
실제 사례: 식물 인포그래픽
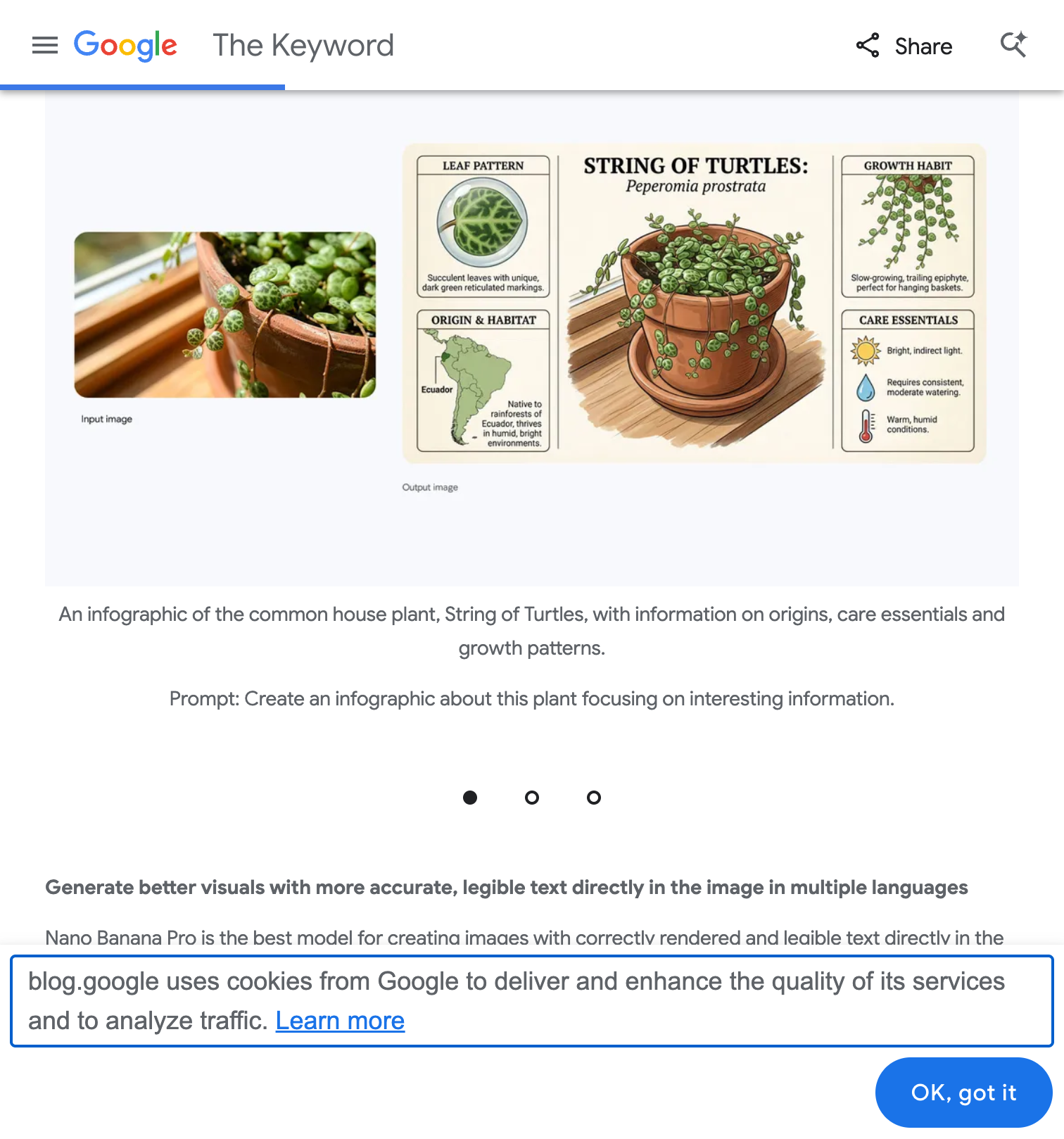
실제 사례: “String of Turtles” 식물 사진 → Leaf Pattern, Origin & Habitat, Growth Habit, Care Essentials 등 실제 정보 기반 인포그래픽 자동 생성 출처: Google Blog
프롬프트 예시: Create an infographic about this plant focusing on interesting information.
이 예시에서 나노바나나 프로는:
- 식물의 실제 학명(Peperomia prostrata) 검색
- 원산지, 성장 습성, 관리 방법 등 실제 정보 기반 시각화
- 깔끔한 레이아웃과 아이콘 자동 배치
사용자 평가
“철자 오류 없이 인포그래픽을 완성했다” “레스토랑 메뉴를 완벽한 레이아웃과 타이포그래피로 한 번에 생성했다”
3.4 스토리보드 & 영상 제작
스토리보드 자동 생성
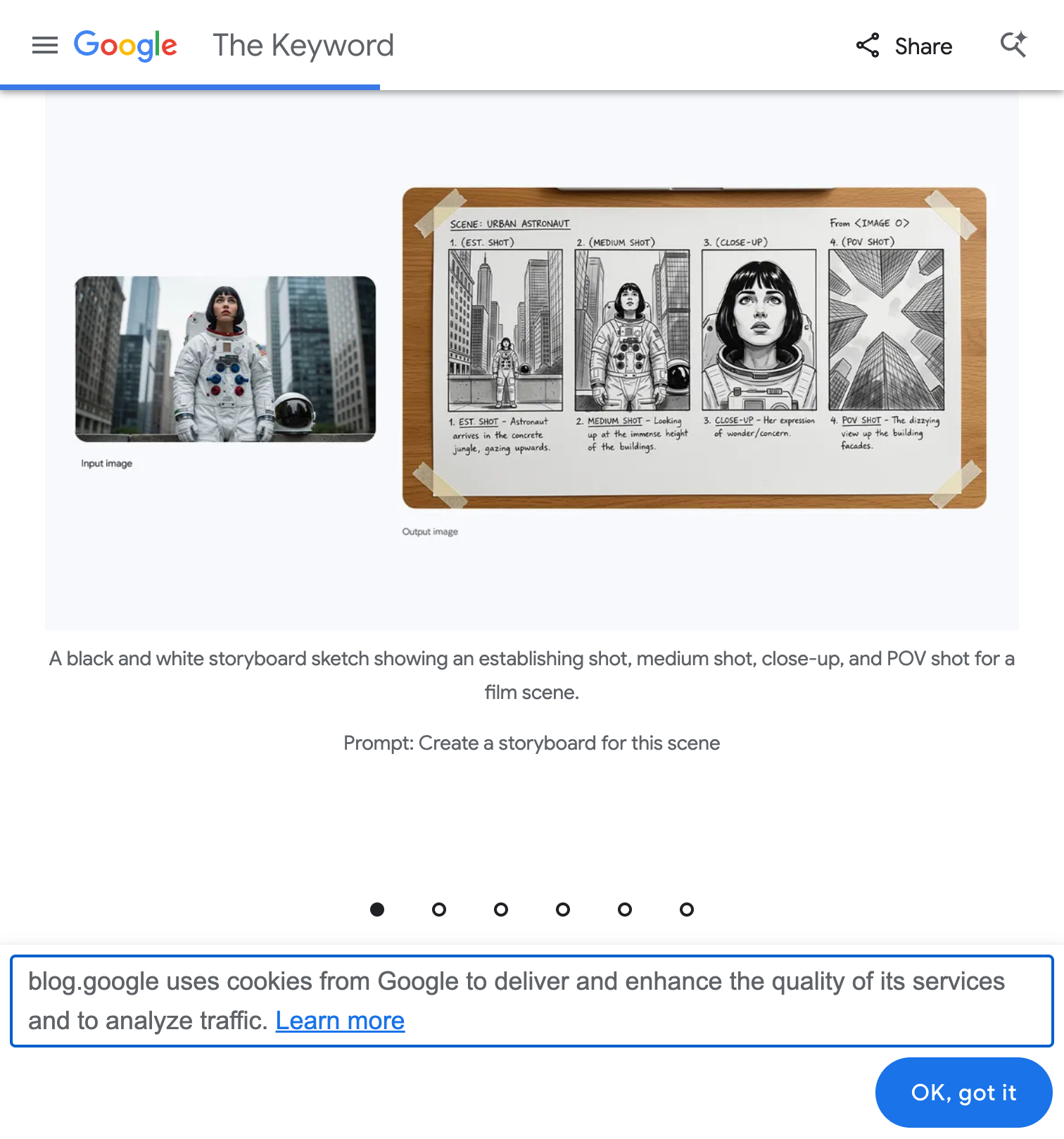
실제 사례: 우주비행사 이미지 한 장 → Establishing Shot, Medium Shot, Close-up, POV Shot 등 영화 촬영 기법에 맞춘 스토리보드 자동 생성 출처: Google Blog
프롬프트 예시: Create a storyboard for this scene
이 기능은 다음과 같은 분야에서 활용됩니다:
- 영화/드라마 프리프로덕션: 촬영 전 장면 구성 시각화
- 광고 제작: 광고 콘티 빠르게 제작
- 유튜브 콘텐츠: 영상 기획 단계에서 활용
3.5 브랜드 일관성 유지
기능
- 최대 14개 참조 이미지 업로드로 스타일 학습
- 로고, 컬러 팔레트, 제품 샷 적용
- 기업 아이덴티티와 캠페인 기준에 맞춘 자산 생성
활용 분야
- 코믹북 제작자: 50개 다른 포즈에서도 캐릭터 얼굴 유지
- 스토리보드 아티스트: 일관된 캐릭터로 시퀀스 제작
- 마케팅 캠페인: 반복되는 캐릭터/마스코트 자산 유지
3.6 글로벌/다국어 캠페인
기능
- 이미지 내 텍스트 번역 및 렌더링 지원
- 마케팅 자료, 제품 패키징, 프로모션 비주얼 즉시 현지화
지원 언어
영어, 중국어(간체/번체), 일본어, 한국어, 프랑스어, 독일어, 스페인어, 이탈리아어, 포르투갈어, 러시아어, 아랍어 등
4. 전문가 리뷰 & 고급 프롬프트 기법
Max Woolf의 심층 리뷰
출처: Max Woolf’s Blog - “Nano Banana Pro is the best AI image generator, with caveats”
고급 프롬프트 엔지니어링

복잡한 제약 조건을 가진 프롬프트도 정확하게 처리: 3마리 고양이의 색상, 포즈, 의상, 배경, 조명까지 모두 지정 출처: Max Woolf’s Blog
위 예시에서 사용된 프롬프트:
Create an image featuring three specific kittens in three specific positions.
All of the kittens MUST follow these descriptions EXACTLY:
- Left: a kitten with prominent black-and-silver fur, wearing both blue denim overalls and a blue plain denim baseball hat.
- Middle: a kitten with prominent white-and-gold fur and prominent gold-colored long goatee facial hair, wearing a 24k-carat golden monocle.
- Right: a kitten with prominent #9F2B68-and-#00FF00 fur, wearing a San Francisco Giants sports jersey.
Aspects of the image composition that MUST be followed EXACTLY:
- All kittens MUST be positioned according to the "rule of thirds" both horizontally and vertically.
- All kittens MUST lay prone, facing the camera.
- All kittens MUST have heterochromatic eye colors matching their two specified fur colors.
- The image is shot on top of a bed in a multimillion-dollar Victorian mansion.
- The image is a Pulitzer Prize winning cover photo for The New York Times with neutral diffuse 3PM lighting for both the subjects and background that complement each other.
- NEVER include any text, watermarks, or line overlays.
핵심 포인트: 나노바나나 프로는 이러한 복잡한 제약 조건들을 모두 정확하게 반영하여 이미지를 생성할 수 있습니다.
5. 추천 프롬프트 예시
피규어 제작
Draw a prospective model of the character in the picture,
commercialized as a 1/7 scale figure.
3D 치비 피규어
3D chibi figurine of character in action pose, glossy vinyl toy finish,
soft pastel color palette, studio lighting with gentle rim light,
floating on solid color background, Funko Pop style,
rendered in Blender quality, 4K detail
상세페이지 제작
제품 주위 배경을 넓게 확장한 뒤에 오피스 공간으로 바꿔줘.
그리고 제품 위에 핀 조명이 은은하게 비췄으면 좋겠어.
인포그래픽 제작
Create an infographic about this plant focusing on interesting information.
스토리보드 제작
Create a storyboard for this scene
이미지 편집
In this picture, remove the person on the left.
Change the background of this image to a beach at sunset.
6. 가격 및 이용 방법
가격표
| 해상도 | 가격(장당) | 비고 |
|---|---|---|
| 1K | $0.134 | GPT-Image-1보다 저렴 |
| 2K | $0.134 | |
| 4K | $0.24 | 프리미엄 품질 |
요금제별 워터마크 정책
| 요금제 | 워터마크 |
|---|---|
| 무료 | 우측 하단 반짝이(Sparkle) 마크 |
| 프로(Pro) | 우측 하단 반짝이(Sparkle) 마크 |
| 울트라(Ultra) | 워터마크 없음 |
접근 방법
- Gemini 앱: Create Image → “Thinking with 3 Pro” 선택
- Google AI Studio: API 접근
- Vertex AI: 기업용 API 통합
- 제3자 플랫폼: ImagineArt, Adobe Creative Cloud
무료 체험 방법
- LM Arena 사이트에서 100% 무료 테스트 가능
- Gemini 무료 버전: 하루 1~3개 생성 가능
7. 장점과 한계
장점
| 항목 | 설명 |
|---|---|
| 텍스트 정확도 | 다국어 텍스트 렌더링 업계 최고 수준 |
| 합성 능력 | 자연스러운 이미지 합성 및 편집 |
| 일관성 | 다중 이미지에서 캐릭터/브랜드 일관성 유지 |
| 속도 | 경쟁 모델 대비 빠른 생성 속도 |
| 지식 통합 | 구글 검색 연동으로 정확한 정보 기반 생성 |
한계
| 항목 | 설명 |
|---|---|
| 한글 완벽도 | 약 90% (100% 아님) |
| 사용량 제한 | Pro 플랜도 20~30개에서 제한되는 경우 보고 |
| 순수 생성 품질 | Text-to-image가 Image-to-image보다 다소 낮음 |
| 정확한 정보 | 지도, 행정구역 등 정확성 요구 요소는 확인 필요 |
8. 추천 대상
강력 추천
- 이커머스 운영자
- 마케팅 에이전시
- 콘텐츠 크리에이터 (유튜버, 블로거)
- 제품 사진 리소스 부족한 브랜드
- 데이터 시각화/인포그래픽 제작자
- 글로벌 다국어 캠페인 운영 팀
사용 시 주의
- 한글 텍스트 최종 확인 필수
- 정확한 정보(지도, 수치 등) 별도 검증 필요
- 복잡한 합성 작업 시 프롬프트 보정 고려
9. 결론
나노바나나 프로는 텍스트 렌더링, 브랜드 일관성, 다국어 지원 측면에서 현존 최고 수준의 AI 이미지 생성 도구입니다. 특히 마케팅 콘텐츠, 이커머스 상세페이지, 인포그래픽 제작에서 생산성을 획기적으로 향상시킬 수 있습니다.
다만 한글 완벽도가 100%는 아니므로, 상업적 활용 시에는 최종 결과물 검토를 권장합니다.
참고 자료
- 구글 공식 블로그 - 나노바나나 프로 소개
- Google Blog - Introducing Nano Banana Pro
- 나무위키 - 나노 바나나
- Max Woolf’s Blog - Nano Banana Pro Review
- Cybernews - Nano Banana Pro Review
- ImagineArt - 24 Mind-Blowing Use Cases
- ImagineArt - Prompt Guide
- Will Francis - Digital Marketing Prompts
- 애드센스팜 - 완벽 가이드
- 캐럿 블로그 - 총정리
이 문서의 스크린샷들은 각 출처 웹사이트에서 직접 캡처한 것입니다.
]]>